
שפת SQL נחשבת כ-Best Practice לשליפת ועיבוד נתונים.
אך כאשר אנחנו רוצים לבצע ניתוח נתונים – לחפש בהם דפוסים, התפלגויות, מאפיינים סטטיסטיים, וזיהוי טווחי ערכים בעלי משמעות מיוחדת, ברוב המקרים שפת SQL כבר אינה מספיקה, ונדרש לעבור לסביבה סטטיסטית, דוגמת SAS/SPSS (בארגונים גדולים), או R בארגונים קטנים יותר, ואפילו לאקסל. נקודת המעבר בין שתי הסביבות (עיבוד נתונים וניתוח נתונים) אינה תמיד חד משמעית, והלכה למעשה גם בכלי הסטטיסטי מתבצע תהליך מסוים של עיבוד נתונים, חישובי משתנים וכיו"ב.סביר להניח, כי אם היו זמינות עבורנו פונקציות סטטיסטיות או אפשרויות ניתוח נתונים גם בסביבת ה-SQL בה אנו עובדים – היינו יכולים לדחות ככל הניתן את שלב המעבר לסביבה הסטטיסטית, מה שהיה יכול לייעל את תהליך עיבוד וניתוח הנתונים כולו.למען האמת – חלק ניכר מתהליך ניתוח נתונים טיפוסי ניתן לביצוע ב-SQL, באמצעות שימוש בפונקציות מובנות בכלי ה-SQL, ובפונקציות ופרוצדורות מותאמות אישית.אחד התהליכים המרכזיים מסוג זה הוא ניתוח נתונים ראשוני של שדות רציפים (מספריים), הכולל הצגת התפלגויות.
עבור משתנים רציפים, על מנת להציג את התפלגות השדה נדרש לחלקו תחילה לקטגוריות.
קיימות מספר טכניקות לבצע זאת, כאשר במאמר זה נציג שתי טכניקות פשוטות.
חלוקה לינארית
בשיטה זו, ניקח את ערך השדה של כל תצפית, נחלק אותו בפרמטר קבוע, נעגל מטה, ונכפיל בחזרה באותו המקדם. כך נקבל התפלגות של התצפיות.
לדוגמה: אם יש לנו משתנה הכנסה (אלפי ₪), נקבל את ההכנסה המעוגלת מטה ל-1,000 הקרוב.
בדוגמה הבאה (נתונים דמיוניים) מוצגת טבלה פשוטה של נתוני לקוחות והכנסה חודשית שלהם. קוד ה-SQL (סביבת SQL Server 2012 Express) מתאר את פעולת החלוקה הלינארית, במקרה זה ב-2,000 (מיוצג בתור הפרמטר @lin_interval).
בעזרת פונקציית REPLICATE (העתקת תו מסוים X פעמים), אפשר לראות ממש את גרף ההתפלגות בתוך SQL (בעזרת משתנה @scale שמתאים את גובה העמודות בגרף).
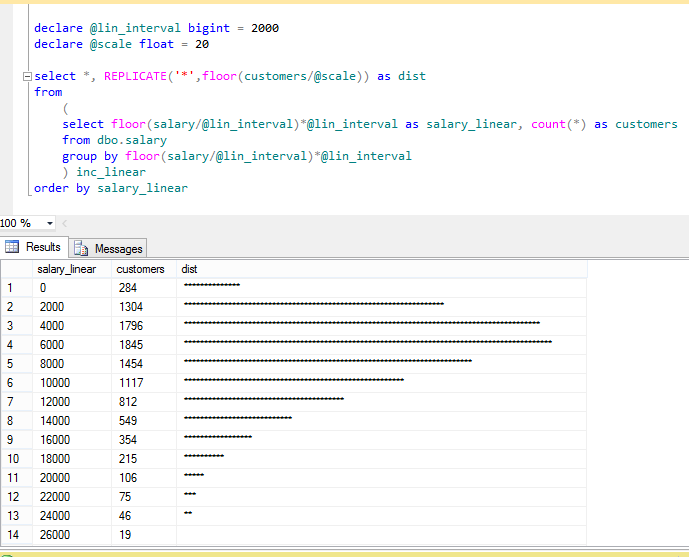 חשוב להדגיש, שהתצוגה האמורה לא באה להחליף כלי ניתוח נתונים או הצגה מסודרת בגרף, אבל מהווה פתרון יעיל למדי לצורך ניתוח נתונים ראשוני.
חשוב להדגיש, שהתצוגה האמורה לא באה להחליף כלי ניתוח נתונים או הצגה מסודרת בגרף, אבל מהווה פתרון יעיל למדי לצורך ניתוח נתונים ראשוני.
חלוקה לוגריתמית
בעוד ששיטת החלוקה הלינארית יעילה מאוד בהצגת ההתפלגות האמיתית של השדה, קיימים עבורה מספר חסרונות. העיקרי שבהם הוא שנדרשים מספר ניסיונות למצוא את הפרמטר הספציפי הנדרש לחלוקה. בדוגמה שלנו, אם היינו בוחרים באינטרוול נמוך מדי – נניח 1,000 – לא היינו יכולים לצפות בכל הגרף, מאחר והיו יותר בו מדי ערכים.
הבעייתיות נובעת מתופעת ה'זנב הימני'. בעוד שלרוב, ערכי שדות מוגבלים משמאל (לדוגמה: משכורת שלילית אינה אפשרית, גיל 18 עבור עובדים אקדמאים למעט מקרים חריגים, זמן ממוצע לצפייה בדף באתר אינטרנט שגדול מ-0 ועוד), אין באמת מגבלה לערכי המקסימום של השדות הללו; מנכ"ל של תאגיד גדול יכול לקבל שכר של מאות אלפי ₪ בחודש, ותיאורטית יכול להיות בחברה מסוימת לקוח או עובד בן 100.
דרך מתוחכמת לפתרון הבעייתיות, היא לבצע חלוקה לפי סרגל לוגריתמי (אינטרוול הולך וגדל), במקום הסרגל הלינארי (אינטרוול קבוע).
הדוגמה הבאה מציגה חלוקה לפי סרגל לוגריתמי עם בסיס 2 (הקבוצות נחתכות לפי חזקות של 2).
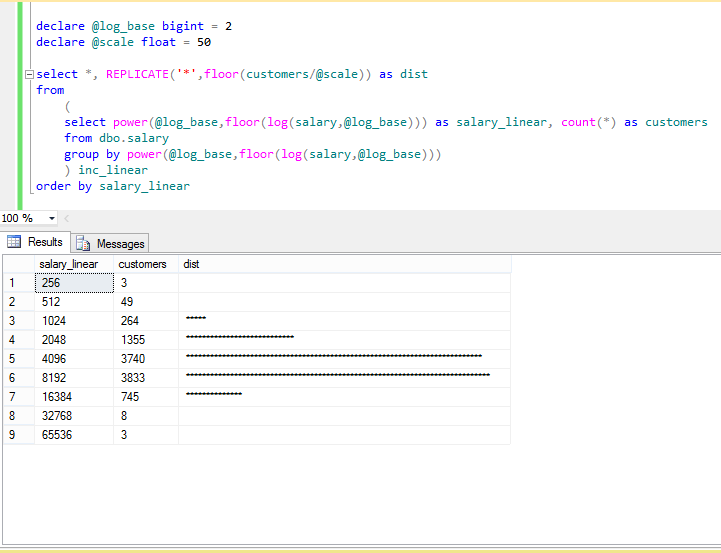
כאן כבר סביר להניח שלא נקבל יותר מ-10-15 קבוצות, והזנב הימני ינוטרל.
לסיכום: ניתן לעשות שימוש ב-SQL גם עבור ניתוח נתונים ראשוני של שדות, ואף מומלץ להוסיף קטגוריות באופן ראשוני לקובץ הניתוח עוד טרם למעבר לסביבה הסטטיסטית.
במאמר הבא נדון בחלוקת משתנים רציפים לקטגוריות לפי אחוזונים, אשר משלבת את 'הטוב משני העולמות' שהוצגו כאן, ובנוסף מאפשרת שימושים רבים אחרים בעולם ה-Predictive Analytics.