
קבוע או יחסי?
במאמר הקודם הצגנו דרך לניתוח נתונים בסיסי הבוחן התפלגות של שדות רציפים לפי איחוד הערכים שלהם בעזרת מקדם קבוע, או חזקה.
החלוקה של המשתנה הרציף למספר קבוצות (Binning) אפשרה להציג את ערכי השדה על גבי גרף – וכך לבצע ניתוח נתונים עבורו. הבעיה בחלוקה על סמך אינטרוול קבוע או משתנה בקצב קבוע, היא שההסתכלות היא על הערך הגולמי (נומינלי) של השדה, והערך הזה אינו תמיד הגורם להתנהגות המשתקפת בנתונים.
נניח שנמצא שנכון להיום בעלי שכר של 5-10 א' ₪ נוטים לקנות מוצר X, ובעלי שכר של 10-15 א' ₪ נוטים לקנות מוצר Y.
עכשיו נניח שבעוד חצי שנה השכר הממוצע יגדל בכ-1,000 ₪. האם גם במצב החדש הקבוצות ומאפייני הצריכה יישארו זהים?
ככל הנראה מאפייני הצריכה יישארו בטווח הקצר דומים, אך יהיה שינוי בקבוצות – 6-11 א' ₪, ו-11-16 א' ₪, בהתאמה.
 על מנת לתת פתרון לתופעה, נוכל להניח מלכתחילה שמה שמעיד על מאפייני ההתנהגות אינו השיוך לקבוצת בעלי שכר לפי הערכים עצמם, אלא שיוך יחסי: בעלי שכר בעשירונים 5-6 נוטים לרכוש את מוצר X, ועשירונים 7-8 את מוצר Y. וכאן אנחנו נכנסים לעולם האחוזונים – מהכלים השימושיים ביותר בידי אנליסט הנתונים הטיפוסי בעת ניתוח נתונים.
על מנת לתת פתרון לתופעה, נוכל להניח מלכתחילה שמה שמעיד על מאפייני ההתנהגות אינו השיוך לקבוצת בעלי שכר לפי הערכים עצמם, אלא שיוך יחסי: בעלי שכר בעשירונים 5-6 נוטים לרכוש את מוצר X, ועשירונים 7-8 את מוצר Y. וכאן אנחנו נכנסים לעולם האחוזונים – מהכלים השימושיים ביותר בידי אנליסט הנתונים הטיפוסי בעת ניתוח נתונים.
באיזה אחוזון אני נמצא?
חישוב הערך שמופיע באחוזון מסוים עבור נתון הוא תהליך פשוט, המופיע כפונקציה מובנית הן באקסל (PERCENTILE), והן ב-SQL Server (פונקציית PERCENTILE_DISC). יחד עם זאת, לצרכי Predictive Analytics נרצה לרוב לבצע חישוב הפוך – באיזה אחוזון נמצאת תצפית מסוימת (לדוגמה: אם ההכנסה שלי היא 15 א' ₪, באיזה עשירון אני נמצא).
ב-T-SQL קיימת פונקציה בשם NTILE, אשר אמורה לתת מענה לחלוקת ערכי שדה מסוים לפי אחוזונים (N קבוצות שוות בגודלן). הבעיה היא, שהמנגנון שלה מתבסס על דירוג של כל ערכי השדה מהנמוך לגבוה (אפשר גם להיפך). במקרה של שתי תצפיות בעלות ערך זהה יבוצע מיון שרירותי, והן תקבלנה דירוג שונה ואף עשירון שונה – מצב שישייך תכונות שונות ל-2 ערכים זהם ואינו סביר מבחינה עסקית.
לצורך המחשת הבעייתיות, נשתמש בדוגמה מהמאמר הקודם – של 10,000 תצפיות של לקוחות עם השכר החודשי שלהם. להלן חלוקה ל-10 קבוצות שוות באמצעות שימוש בפונקציית NTILES:
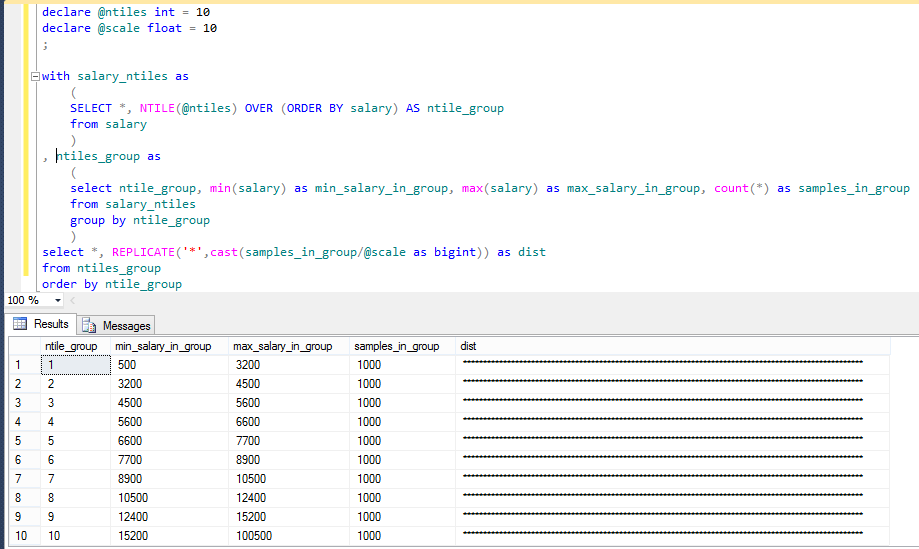
ניתוח נתונים בדוגמה יראה באופן ברור, שבעוד שבכל קבוצה יש בדיוק 1,000 תצפיות. יחד עם זאת, הערך המקסימלי של כל קבוצה זהה לערך המינימלי בקבוצה הבאה – מה שמעיד בודאות על קיום תצפיות בעלות ערך זהה בשתי קבוצות שונות – ועל כן החלוקה אינה נכונה עבור הצרכים שלנו.
קובץ הקוד (סביבת SQL Server 2012 Express).
הפרד ומשול
הדרך לפתור זאת היא באמצעות שיוך כלל הערכים בעלי אותו הערך לקבוצת האחוזון הנמוכה ביותר.
באופן זה, כל ערך ישויך באופן חד-ערכי לקבוצה אחת בלבד, כך שכל קבוצה תקבל בדיוק את אותן התכונות.
חשוב להבין, שתחת שיטה זו מספר התצפיות בכל קבוצה מן הסתם לא יהיה זהה (אם חצי מהאוכלוסייה היא בעלת אותו הערך, גודל הקבוצה אליה ישתייכו יהיה גבוה יותר מיתר הקבוצות). ועדיין, זה הכי קרוב שניתן לקבוצות בעלות גודל דומה, ועם אותן התכונות לכל קבוצה – המאפיין הרצוי עבור תהליך ניתוח נתונים אפקטיבי.
להלן השליפה המבצעת את התיקון:

בשליפה יש 4 שלבים:
- Salary_ntiles– חישוב האחוזון עבור כל תצפית – כמו מקודם.
- Ntiles– אגרגציה של האחוזונים – כמו מקודם.
- Salary_ntiles_min– מציאת ערך האחוזון המינימלי עבור כל ערך של שדה השכר, כך שכלל התצפיות בעלות אותו הערך תשויכנה בדיוק לאותה הקבוצה.
- מיזוג בין טבלת השכר לטבלת האחוזונים המתוקנת.
- שליפת האגרגציה לפי קבוצות האחוזונים המתוקנות.
להלן תוצאת השליפה:
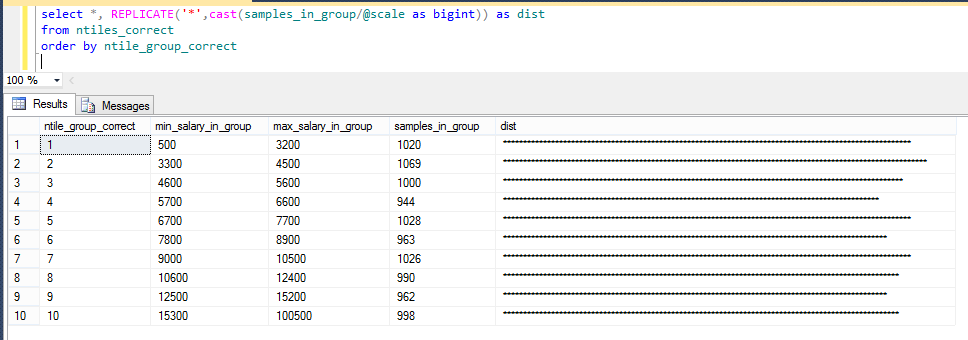
כאן כל רמת שכר היא כבר חד-ערכית, קרי – משויכת לקבוצת אחוזונים אחת בלבד.
ניתן לראות, כי גודל הקבוצות אינו זהה – כנובע מהתיקון – אבל עדיין בסדרי גודל דומים.
כעת אנחנו יכולים להמשיך לבצע ניתוח נתונים באופן רגיל, ולהיות בטוחים שעבור כל קבוצה מבוססת אחוזונים יש בדיוק את אותן התכונות – דוגמת קורלציה עם גיל, נטייה לרכישת מוצר מסוים, או כל התנהגות אחרת שנרצה לחקור.