
Big-Data הוא ללא ספק אחד מהתחומים המובילים ביצירת באז בשנים האחרונות. התחום מדבר על עיבוד של נפחי נתונים גדולים מאוד בקצבים מהירים ביותר, והפקת תובנות מנתונים אלה.
אחת מהתפיסות הדרמטיות שפותחו לעבודה עם Big-Data היא NoSQL, אשר מהווה שינוי מהותי מהעולם הרלציוני שהיה קיים עד היום.
בסדרת מאמרים זו יוצגו עיקרי תפיסת ה-Big-Data, כולל רכיבים עיקריים בה, דוגמת Hadoop,
In Memory Databases, ו-NoSQL Databases, כולל הדגמה למספר כלים מייצגים.

ישן מול חדש
בעולם המסורתי של בסיסי הנתונים הרלציוניים (RDBMS), הארגון עשה שימוש בנתונים מובנים (טבלאיים), שהגיעו בקצבים סבירים ובהיקפים סבירים. לבסיסי הנתונים היה מבנה ברור, קשרים ברורים בין הטבלאות ואפשרות לאחזר ולעדכן רשומה בודדת בכל טבלה – בעזרת שפת SQL.
כאשר נכנסו לתמונה בעשור האחרון הרשתות החברתיות, חברות אינטרנט המספקות תוכנה כשירות (SaaS), אפליקציות מובייל וסנסורים שונים המפיקים נתונים – המבנה של בסיס הנתונים הרלציוני הפך באחת מיתרון לעול – מאחר ואילוצי מודל הנתונים הרלציוני כבר לא אפשרו שמירה ואחזור מהירים של הנתונים בנפחים ובקצבים הנדרשים.
לסוגיה נמצאו פתרונות בשני מימדים:
- להתחיל לעבוד מול זיכרון מהיר (In Memory DB).
- לשנות לחלוטין את מבנה הנתונים על מנת שיתאים לעיבוד נתונים בנפח ובקצב גבוה (Hadoop and NoSQL).
In Memory Databases
 כאשר מדברים על שימוש בזיכרון– העיקרון פשוט מאוד: יותר זיכרון = יותר מהירות. לדוגמה: אם יש לך במחשב 4GB של זיכרון פנימי, ותגדיל אותו ל-8GB – הביצועים לרוב יהיו מהירים יותר. בנוסף – אם תחליף את הכונן הקשיח שברשותך מכונן סטנדרטי לכונן SSD – הביצועים ישופרו מהותית. המחיר לעיבוד נתונים רבים בזיכרון הוא עלות גבוהה, ולכן הפתרון פחות מתאים בתור פתרון יחיד לנפחי נתונים אדירים;
כאשר מדברים על שימוש בזיכרון– העיקרון פשוט מאוד: יותר זיכרון = יותר מהירות. לדוגמה: אם יש לך במחשב 4GB של זיכרון פנימי, ותגדיל אותו ל-8GB – הביצועים לרוב יהיו מהירים יותר. בנוסף – אם תחליף את הכונן הקשיח שברשותך מכונן סטנדרטי לכונן SSD – הביצועים ישופרו מהותית. המחיר לעיבוד נתונים רבים בזיכרון הוא עלות גבוהה, ולכן הפתרון פחות מתאים בתור פתרון יחיד לנפחי נתונים אדירים;
היכן In Memory כן יעיל? כאשר נפח הנתונים אינו גדול מדי והיכן שנדרשת עמידה בקצב גבוה של הגעה/ עיבוד נתונים או בדרישה ל-Time to Market מהיר. להלן מספר דוגמאות:
- יישומי Real Time (אם נכתוב משהו בפייסבוק או בטוויטר – לא נוכל להמתין דקה, ואפילו לא 10 שניות לפרסום…).
- בסיסי נתונים רלציוניים בעלי נפח נמוך יחסית, אשר רוצים להגדיל בהם את קצב העיבוד.
- ניתוח נתונים מובנים והצגתם ב-Dashboards ו/או גרפים מתוך נתונים מסוכמים (לדוגמה: מספר המשתמשים בכל שעה).
Hadoop and NoSQL
כפי שצוין, הצורך בטיפול בנפחי נתונים גבוהים חייב שינוי מהותי מהעולם הרלציוני. גישת הפתרון הורכבה ממספר עקרונות שטיפלו ב'מבזבזי הזמן' המשמעותיים בבסיסי הנתונים הרלציוניים:
- ביטול מודל הנתונים – ושמירת נתונים בצורה גולמית – מבלי להבנות אותם (Schemaless).
- ויתור על פעולות מסיביות בין טבלאות – בדגש על הצלבת טבלאות (Join\Merge).
- הגבלת היכולת לעדכן רשומות ספציפיות (טרנזאקציות).
- מעבר מסריקת טבלה שלמה על כל העמודות שבה (גם עבור שאילתה הדורשת שימוש בעמודה אחת בלבד מתוך כל הטבלה), לסריקה לפי עמודות.
- במקום התבססות על שרת אחד מרכזי אשר מעבד נתונים באופן טורי – עיבוד במקביל של הנתונים על פני מספר רב של מכונות (לעתים אלפים), בפרט תוך שימוש ביכולות המחשוב בענן (Cloud).
התוצאה היתה תפיסה ו-Toolbox חדשים לשמירה ועיבוד נתונים מקבילי בשם Hadoop, וכן בסיסי נתונים מדור חדש בשם NoSQL.
Hadoop
תפיסת ה-Hadoop הובאה ישירות ממתודולוגיית העבודה של Google. המהות של הכלי הוא שמירה ועיבוד של נתונים במקביל על פני מספר רב של מכונות (תפיסה מבוזרת) – לעומת שמירה ועיבוד בשרת ארגוני יחיד.
המימוש של Hadoop כולל שני היבטים עיקריים:
- חלוקה של הנתונים לתתי חלקים ואחסון שלהם על פני מספר רב של מכונות (HDFS).
- תהליך עיבוד הנתונים באופן מקבילי (Map-Reduce).
HDFS
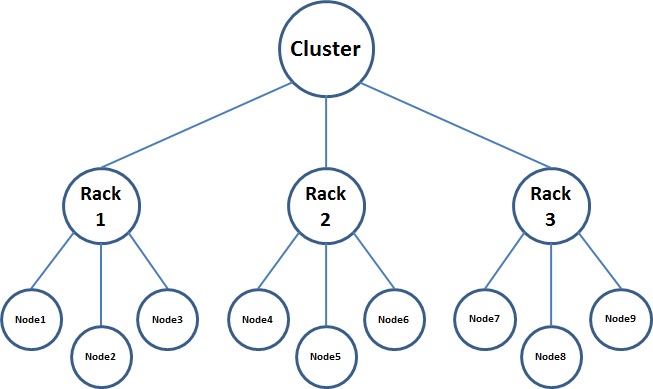 לצורך אחסון נתונים באופן מבוזר, פותח מבנה קבצים בשם HDFS
לצורך אחסון נתונים באופן מבוזר, פותח מבנה קבצים בשם HDFS
(Hadoop File System). לפי מבנה זה, חלוקת הנתונים לתתי חלקים מבוצעת באופן אוטומטי בהסתמך על בלוקים של קטעי מידע, כאשר כל מקטע משויך למכונה מסוימת (Node), כל מכונה משויכת למאגר של מכונות (Rack), וכלל המערכת נקראת אשכול (Cluster). מעבר למבנה הפיזי של אשכול המכונות, ה-HDFS כולל גם את אלגוריתם החלוקה למקטעי המידע, סנכרון בין המכונות השונות והכפלת קטעי המידע לצרכי גיבוי (במקרה שנופלת מכונה אחת או יותר).
Map Reduce
בשרת ארגוני יחיד, השאילתות מבוצעות באופן טורי – בהתאם לתהליך העיבוד הנדרש. ב-Hadoop לעומת זאת, הנתונים נשמרים במספר רב של מכונות, ולכן כל תהליך עיבוד מחייב הפעלה של המכונות באופן ייחודי עבורו – אשר לא בהכרח ידרוש להפעיל את כלל המכונות באשכול. לצורך כך פותחה תפיסת ה-Map-Reduce. התפיסה כוללת שני שלבים עיקריים:
- מיפוי תהליך הנתונים הנדרש (Map)
- מיפוי המכונות הרלוונטיות לתהליך.
- תהליך הנתונים הנדרש בכל אחת מהמכונות.
- מה עושים במקרה שמכונה נופלת לפני שסיימה את העיבוד על הנתונים שבה.
- סיכום הנתונים שהוחזרו מכלל המכונות (Reduce)
- קבלת הנתונים מכלל המכונות שנכללו בתהליך העיבוד.
- סיכום הנתונים לפי האלגוריתם שאופיין בתהליך המיפוי.
על מנת להמחיש באופן פשוט את עקרון ה-Map-Reduce, להלן דוגמה לתרחיש בבסיס נתונים רלציוני. נניח שאנחנו רוצים לחשב כמה לקוחות הגרים בת"א היו פעילים בחברה שלנו בכל חודש. נניח שבסיס הנתונים בחברה כולל שתי טבלאות: טבלת לקוחות (מספר לקוח, עיר מגורים), וטבלת פעילות לקוחות (מספר לקוח, שנה וחודש, מדדי פעילות). [השדות עם הקו התחתון הם שדות מפתח]. עוד נניח, שיש לנו נתונים של 5 שנים (60 חודשים).
תחת התפיסה הרלציונית, נידרש לתהליך ה-SQL הבא:
- סינון טבלת הלקוחות לפי עיר מגורים = ת"א.
- הצלבה של טבלת הלקוחות המסוננת עם טבלת פעילות הלקוחות – לפי שדה מספר לקוח.
- קיבוץ (אגרגציה) של הטבלה המשותפת לפי השדה 'שנה וחודש'.
עכשיו נניח, שיש לנו 10 מיליון לקוחות, ושהם משתנים מחודש לחודש. בנפחים אלה, ייתכן שהצלבת כל טבלת הלקוחות עם כל טבלת פעילות הלקוחות (בכלל החודשים) תגזול משאבים רבים ותארך זמן רב.
עכשיו נניח שהנתונים הועברו ל-Hadoop, ונתוני כל לקוח (משתי הטבלאות, בכל החודשים) נשמרים במכונה אחת בלבד – לפי החודש והשנה שבהם הצטרף לשירות.
בשלב ה-Map יוגדר התהליך עבור כלל המכונות, כאשר בכל מכונה תתבצע פעולה דומה – כמו בגישה הרלציונית שהוצגה קודם. בסיום שלב זה, תקבל המכונה המסנכרנת תשובות מכל אחת מיתר המכונות (60 במספר). לאחר קבלתן, יחל שלב ה-Reduce, בו במקרה זה תתבצע סכימה של כמות הלקוחות, תוך אגרגציה לפי חודש (כל לקוח כאמור יוכל להופיע רק בפלט של מכונה מסוימת).
באופן זה, השאילתה תרוץ במקביל על 60 המכונות, כאשר כל מכונה תטפל באופן גס ב-1/60 מהלקוחות (נניח שקצב הגיוס/נטישה של לקוחות אחיד) – מה שלכאורה יכפיל את קצב הריצה של השאילתה פי 60.
כתיבת תהליכי Map-Reduce
קיימות 3 דרכים עיקריות לכתוב תהליכי Map-Reduce ב-Hadoop:
- כתיבה ישירה של התהליך ב-Java – הכי יעיל בהיבט ביצועי התהליך, אך פחות רלוונטי עבור מדען נתונים טיפוסי.
- כתיבה של התהליך בשפת ה-Script של Hadoop בשם Pig.
- כתיבת שאילתה בממשק דמוי SQL של Hadoop בשם Hive.
לאור הקרבה לשפת SQL, השימוש ב-Hive הוא הנפוץ ביותר בקרב מדעני נתונים, ומומלץ להתחיל לפעול בעולם ה-Hadoop באמצעות ממשק זה.
NoSQL
 בעוד ש-Hadoop פונה בעיקר לתהליכי Batch הדורשים טיפול במסות אדירות של נתונים, התשתית מתאימה פחות לפעילות ברמת הרשומה הבודדת – בפרט בזמן אמת. כנובע מהצורך בטיפול ברמה זו, החלו להופיע סוגים רבים של בסיסי נתונים מדור חדש, אשר שילבו את התפיסה המבוזרת של Hadoop עם הצורך באחסון, שליפה ועיבוד מהירים של נתונים רבים (חלקם באמצעות שילוב של טכנולוגיית In Memory שהוזכרה קודם לכן). בסיסי נתונים אלה מכונים NoSQL.
בעוד ש-Hadoop פונה בעיקר לתהליכי Batch הדורשים טיפול במסות אדירות של נתונים, התשתית מתאימה פחות לפעילות ברמת הרשומה הבודדת – בפרט בזמן אמת. כנובע מהצורך בטיפול ברמה זו, החלו להופיע סוגים רבים של בסיסי נתונים מדור חדש, אשר שילבו את התפיסה המבוזרת של Hadoop עם הצורך באחסון, שליפה ועיבוד מהירים של נתונים רבים (חלקם באמצעות שילוב של טכנולוגיית In Memory שהוזכרה קודם לכן). בסיסי נתונים אלה מכונים NoSQL.
חשוב להבין, ש-NoSQL – אין משמעותו שבסיסי הנתונים הרלציוניים נעלמו באחת מן העולם; המשמעות היא שהם מסוגלים לתת מענה לצרכים בסיסיים, בהם כמויות הנתונים הן סבירות, אך עבור משימות מסוימות – בהן צפויים נפחי נתונים גבוהים מאוד בקצבים מהירים – נדרשת תפיסה שונה (NoSQL = Not Only SQL).
עד כאן מאמר זה. במאמר הבא יוצגו 4 הסוגים המרכזיים של בסיסי הנתונים מבוססי NoSQL.